
WARNING
This article was last updated on 2025-01-31. Please note that the content may no longer be applicable.
As widely known, although Hexo is an excellent static blog framework, due to Node.js characteristics, Hexo consumes significantly more memory during compilation compared to Hugo. This poses a significant challenge for servers with limited resources. Issues like #5522 and #2165 have highlighted this problem. Is this the limit of Hexo’s capabilities? Not at all. Let me show you how I managed to reduce Hexo’s memory consumption by 30%.
First, let me introduce my environment and how I conducted the benchmark.
My environment specifications:
1 | OS: Windows_NT 10.0.22631 x64 |
I tested Hexo version 7.3.0 and my custom built branch test/latest. The theme used was hexo-theme-landscape. Test articles were generated using hexo-many-posts. The following script and commands were used for testing:
1 | const cli = require('hexo-cli'); |
1 | node --trace-gc test/benchmark.js > gc-log.log |
After cleaning and processing the collected logs, the following results were obtained:
1x hexo-many-posts
4x hexo-many-posts
12x hexo-many-posts
Evidence shows that Hexo’s memory consumption has indeed decreased significantly, but how was this achieved?
Optimizing String Concatenation
Related PR: hexo#5620
Looking at the chart above, we can see that during the blog generation process, memory usage rapidly increases in the middle section, forming the first peak. Through investigation, I found that this rapid memory growth phase actually occurs in the PostRenderEscape.escapeAllSwigTags function within Hexo’s lib/hexo/post.ts file.
Let’s examine the code in this class:
1 | class PostRenderEscape { |
Hexo’s Markdown rendering process works as follows:
- Highlight code-fence in Markdown using highlight.js/Prism.js
- Escape Swig tags and highlighted code blocks in Markdown to prevent them from being rendered by the Markdown renderer
- Render Markdown to HTML string using renderers like
hexo-renderer-marked,hexo-renderer-markdown-it, etc. - Render HTML string using nunjucks to process Tag tags
- Unescape Swig tags and highlighted code blocks in the HTML string to generate the final HTML
The PostRenderEscape.escapeAllSwigTags function uses a state machine to escape Swig tags in Markdown. However, the implementation of this function is not very efficient, as you can see, it uses many string concatenation operations output += xxx, which can lead to rapid memory growth. To investigate this issue further, we need to understand how strings are stored in the v8 engine.
Strings in v8
To ensure performance, string implementation in v8 is very complex, using multiple types to store strings:
STRING_TYPE: Standard string, stored using 2 bytesONE_BYTE_STRING_TYPE: String containing only ASCII/Latin1 characters, stored using 1 byteINTERNALIZED_STRING_TYPE: Internalized string, used to store constant stringsEXTERNAL_STRING_TYPE: External string, located outside the v8 heapCONS_STRING_TYPE: Used to store concatenated strings, using Rope data structure to reduce memory usageSLICED_STRING_TYPE: Used to store substrings, using pointers and offset to point to the original string to reduce memory usageTHIN_STRING_TYPE: When a string needs to be internalized but cannot be internalized in place, v8 creates a ThinString object that uses pointers to point to the internalized string
As we can see, the v8 engine chooses appropriate storage methods based on string content and length to reduce memory usage. When using the += operator for string concatenation, the v8 engine converts it to CONS_STRING_TYPE. Each ConsString is actually a binary tree, with the left and right subtrees storing the left and right halves of the concatenated string respectively. The advantage of this data structure is that it can complete string concatenation operations in O(log n) time complexity, and because it uses pointers to share the same string segments, it can reduce memory usage.
However, ConsString also has some drawbacks: each ConsString requires an additional 32 bytes of memory. You can verify this through the following method:
1 | node --allow-natives-syntax |
Assuming each article has 5,000 characters and there are 4,000 posts, ConsString will consume an additional 5,000 * 4,000 * 32B = 640MB of memory. This explains why memory usage increases rapidly when Hexo renders Markdown.
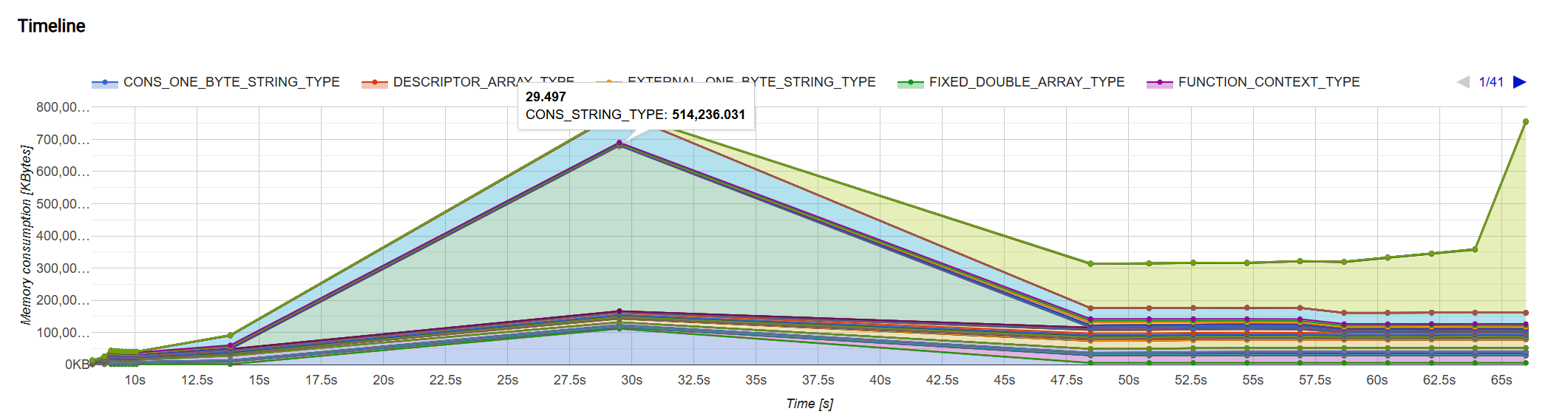
Optimizing String Concatenation
The simplest strategy is to force a flatten operation on the output string after concatenation. The flatten operation converts CONS_STRING_TYPE to ONE_BYTE_STRING_TYPE, thus reducing memory usage.
JS doesn’t provide a direct API for flatten operations, but we might be able to achieve this through:
str[0]orstr.charAt(0)accessing string characters by indexstr.lengthreading lengthNumber(str),str | 0,parseInt(str)converting string to numberreg.test(str)matching string with regular expression
However, this approach isn’t very safe because the v8 engine might optimize strings, causing the flatten operation to fail. Through testing, I found this method highly unreliable, with even minor Node version changes potentially causing flatten operations to fail.
So, besides this method, what other ways do we have to optimize string concatenation? The simplest solution is to write a StringBuilder class for storing concatenated strings. The implementation is very simple:
1 | class StringBuilder { |
By using the StringBuilder class, we can replace output += xxx with sb.append(xxx), thus reducing memory usage. The advantage of this approach is that we can manually call the toString method after concatenation, bypassing ConsString. However, this method causes a slight performance loss. In my opinion, this performance trade-off is worthwhile as it significantly reduces memory usage.
Through this method, we successfully reduced Hexo’s memory consumption:
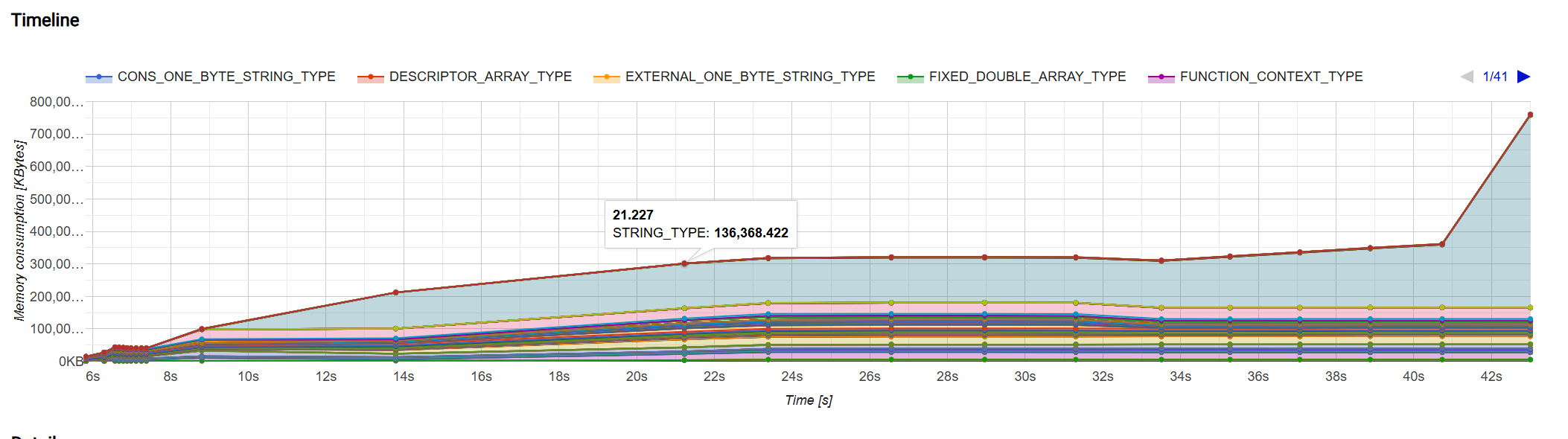
Optimizing File Writing
Related PR: warehouse#277
Besides the intermediate memory usage issue, Hexo’s memory also spikes at the end of the generation phase. This quickly reminded me that Hexo writes all warehouse data to db.json before exiting for hot startup. Looking at the export-related code:
1 | // database.ts |
The above code is very straightforward: it deep clones all data from each Model, converts it to a JSON string, and writes it to a file. However, this approach leads to memory spikes because all data needs to be converted to JSON strings and passed between multiple functions before writing to the file. This implementation doesn’t work well with escape analysis optimization, resulting in memory spikes.
To reduce memory usage, the best strategy is to change string writing to stream writing. This way, we can convert the Model to JSON and write it to the file simultaneously while performing deep cloning:
1 | function asyncWriteToStream<T>(stream: Writable, chunk: T): Promise<unknown> | null { |
We changed the toJSON method to toJSONStream method, which abandons the approach of converting all data to JSON strings at once. Instead, it converts data to JSON strings and writes to file while iterating through the data. This approach confines the cloned objects and generated JSON strings within a single function, which is beneficial for v8 engine’s escape analysis. Combined with stream writing, it can effectively reduce memory usage.

Leave a comment