
WARNING
本文最后更新于 2025-01-31,请注意文中内容可能已不适用。
众所周知,Hexo 虽然是一个非常优秀的静态博客框架,但是由于 Node.js 的特性,Hexo 在编译的时候相比于 Hugo 会占用大量的内存,这对于一些配置较低的服务器来说是一个很大的问题。#5522、#2165 等 ISSUE 也反映了这个问题。难道这就是 Hexo 的极限了吗?当然不是,下面我就来介绍一下我是如何让 Hexo 占用的内存减少 30% 的。
首先,介绍一下我的环境和我是如何进行 benchmark 的。
我的环境为:
1 | OS: Windows_NT 10.0.22631 x64 |
Hexo 版本为 7.3.0 和我自己的构建的分支 test/latest。主题为 hexo-theme-landscape。测试文章使用 hexo-many-posts。使用如下脚本和命令进行测试:
1 | const cli = require('hexo-cli'); |
1 | node --trace-gc test/benchmark.js > gc-log.log |
将收集到的日志进行清洗,得到如下结果:
1x hexo-many-posts
4x hexo-many-posts
12x hexo-many-posts
事实证明,Hexo 的内存占用确实减少了许多,但这是如何做到的?
优化字符串拼接
相关 PR:hexo#5620
查看上面的图标,可以看到在整个博客生成的过程中,中间部分内存迅速增长,形成了第一个顶峰。通过一些调查,我发现这个内存快速增长的阶段实际上位于 Hexo 的 lib/hexo/post.ts 文件中的 PostRenderEscape.escapeAllSwigTags 函数中。
那么,我们就来看看这个类中的代码:
1 | class PostRenderEscape { |
Hexo 渲染 Markdown 的流程是这样的:
- 将 Markdown 中的 code-fence 使用 highlight.js/Prism.js 进行高亮
- 对 Markdown 中的 Swig 标签和高亮完成的代码块进行转义,以避免被 Markdown 渲染器渲染
- 将 Markdown 使用诸如
hexo-renderer-marked、hexo-renderer-markdown-it等渲染器渲染为 HTML 字符串 - 使用 nunjucks 渲染 HTML 字符串,用于处理 Tag 标签
- 将 HTML 字符串中的 Swig 标签和高亮完成的代码块进行反转义,生成最终的 HTML
而 PostRenderEscape.escapeAllSwigTags 函数使用状态机对 Markdown 中的 Swig 标签进行转义。但是,这个函数的实现方式并不是很高效,你可以看到,它使用了大量的字符串拼接操作 output += xxx,这可能导致内存的快速增长。为了深究这个问题,我们需要了解 v8 引擎中的字符串存储方式。
v8 中的字符串
为了保证性能,v8 中字符串的实现方式非常复杂,其使用了多种类型来存储字符串:
STRING_TYPE: 标准的字符串,使用 2 个字节存储ONE_BYTE_STRING_TYPE: 仅包含 ASCII/Latin1 字符的字符串,使用 1 个字节存储INTERNALIZED_STRING_TYPE: 内部化字符串,用于存储常量字符串EXTERNAL_STRING_TYPE: 外部字符串,位于 v8 堆外CONS_STRING_TYPE: 用于存储拼接后的字符串,其使用了 Rope 数据结构以减少内存占用SLICED_STRING_TYPE: 用于存储字符串的子串,其使用了指针和 offset 来指向原始字符串,从而减少内存占用THIN_STRING_TYPE: 当一个字符串需要被内部化而无法在原地进行内部化时,v8 会创建一个 ThinString 对象,其使用了指针来指向内部化后的字符串
由此可见,v8 引擎在处理字符串时,会根据字符串的内容和长度来选择合适的存储方式,以减少内存占用。而使用 += 运算符进行字符串拼接时,v8 引擎会将其转换为 CONS_STRING_TYPE 类型。每个 ConsString 实际上是一个二叉树,其中的左子树和右子树分别存储了拼接后的字符串的左半部分和右半部分。这种数据结构的好处是,可以在 O(log n) 的时间复杂度内完成字符串的拼接操作,且由于使用了指针共享相同的字符串片段,因此可以减少内存占用。
但是,ConsString 也有一些缺点:每个 ConsString 需要额外占用 32 字节的内存。你可以通过以下方式来验证:
1 | node --allow-natives-syntax |
假设每篇文章有 5,000 个字符,共有 4,000 个帖子,那么 ConsString 将占用额外的 5,000 * 4,000 * 32B = 640MB 的内存。这就是为什么在 Hexo 渲染 Markdown 时,内存会迅速增长的原因。
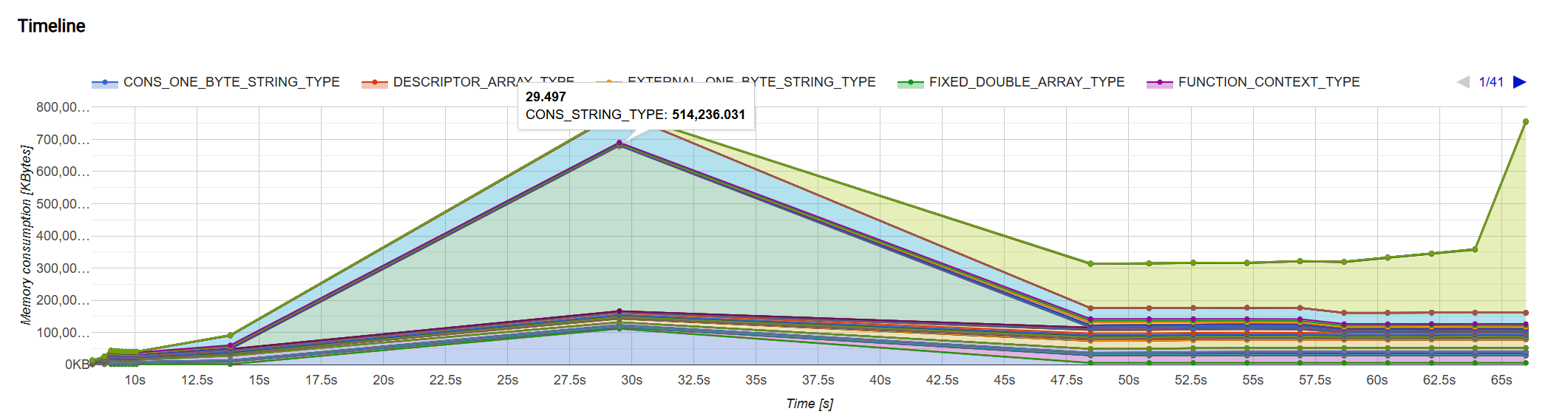
优化字符串拼接
最简单的一个策略是在拼接完 output 字符串后,强制对其进行展平操作(Flatten)。展平操作会将 CONS_STRING_TYPE 转换为 ONE_BYTE_STRING_TYPE,从而减少内存占用。
JS 中并没有直接提供展平操作的 API,但我们可能可以通过以下方式来实现:
str[0]或str.charAt(0)使用索引访问字符串的字符str.length读取长度Number(str)、str | 0、parseInt(str)将字符串转换为数字reg.test(str)使用正则表达式匹配字符串
但是,这种方式并不是很安全,因为 v8 引擎可能会对字符串进行优化,从而导致展平操作失败。经过测试,我发现这种方法非常不可靠,甚至 Node 的小版本变化都可能导致展平操作失败。
那么,除了这个方法之外,我们还有什么办法来优化字符串拼接呢?最简单的方法就是手写一个 StringBuilder 类,用于存储拼接后的字符串。这个类的实现方式非常简单:
1 | class StringBuilder { |
通过使用 StringBuilder 类,我们可以将 output += xxx 替换为 sb.append(xxx),从而减少内存占用。这种方式的好处是,我们可以在拼接完字符串后,手动调用 toString 方法,从而绕过 ConsString。但是,这种方式会造成轻微的性能损失。不过,这种性能损失在我看来是值得的,因为它可以减少大量的内存占用。
通过以上方法,我们成功地削减了 Hexo 的内存占用:
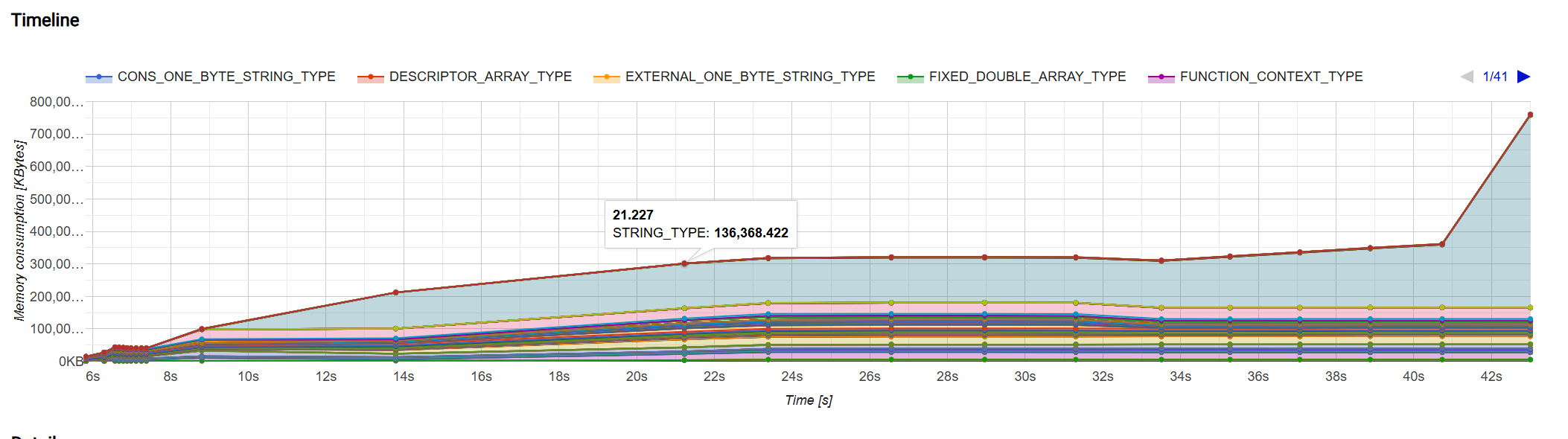
优化文件写入
相关 PR:warehouse#277
除了中间内存占用的问题,Hexo 在生成阶段的结束阶段内存也会飙升。这让我很快就联想到了 Hexo 会在退出之前将 warehouse 中的数据全部写进 db.json 中用于热启动。查看导出相关的代码:
1 | // database.ts |
以上代码非常好理解:将每个 Model 中的所有数据全部深克隆,并将其转换为 JSON 字符串,然后写入文件。但是,这种方式会导致内存飙升,因为在写入文件之前,需要将所有数据全部转换为 JSON 字符串,并在多个函数之间进行传递。这种写法对逃逸分析的优化效果并不好,由此导致了内存飙升。
想要减少内存占用,最好的策略是将字符串写入改为流式的写入。这样,我们就可以在对 Model 进行深克隆的同时,将其同时转换为 JSON 并写入文件:
1 | function asyncWriteToStream<T>(stream: Writable, chunk: T): Promise<unknown> | null { |
我们将 toJSON 方法改为了 toJSONStream 方法,该方法摒弃了将所有数据转换为 JSON 字符串的方式,而是在遍历数据的同时,将其转换为 JSON 字符串并写入文件。这种方式将克隆出的对象和生成的 JSON 字符串的作用于限定在了一个函数内,有利于 v8 引擎的逃逸分析,再配合上流式写入,可以有效减少内存占用。

说些什么吧!